My Google PhD internship experience
My internship research project at Google on machine learning for video compression.
I wrote about how I prepared for and passed the Google coding interview here.
Internship summary
For my summer 2022 internship project at Google, I worked on the Open Codecs team under the Google Chrome umbrella, researching nonlinear transform methods using machine learning (e.g. deep nets) for video compression. The model I developed works on intra-frame prediction residuals, and largely draws inspiration from my PhD research on adaptive gain control, and Ballé et al. (2020).
Some general takeaways:
- Most PhD projects were research oriented compared to e.g. undergrad intern projects, and I had tons of freedom to explore my own ideas.
- Everyone on my team was very nice and helpful, and seemed to have a healthy work-life balance.
- Bay Area summer weather is pretty much unbeatable, but day-to-day life was sleepy compared to NYC.
- The internship (12-14 weeks) goes by very fast, especially since onboarding takes at least a couple weeks.
- TensorFlow 2.0 is a pain to use and debug compared to PyTorch, but
tensorflow.datais very nice. - Modern video codecs are built upon decades of heuristics and incremental engineering improvements.
- Because of hardware limitations, we are far from end-to-end machine learning-based video codecs. The current state-of-the-art is a mostly traditional signal processing with maybe a few ML modules sprinkled in. The discrete cosine transform (DCT) is simply too cheap to replace with a neural network for now.
- Google has one giant monorepo, so you can see everybody’s code. This was very useful when I was stuck on some infrastructural issue (e.g. distributed model training) and needed examples to copy and modify.
- All internal Google tools felt like they were either in Beta, or in some stage of deprecation. It was really frustrating to follow some approved tutorial only to find that it was out-of-date and there was some new way of doing things.
- Google’s code review tools (Critique, Gerrit) are way nicer than GitHub PR reviews.
- Fig, Google’s distributed version control system based on Mercurial, is so much better than Git.
My project
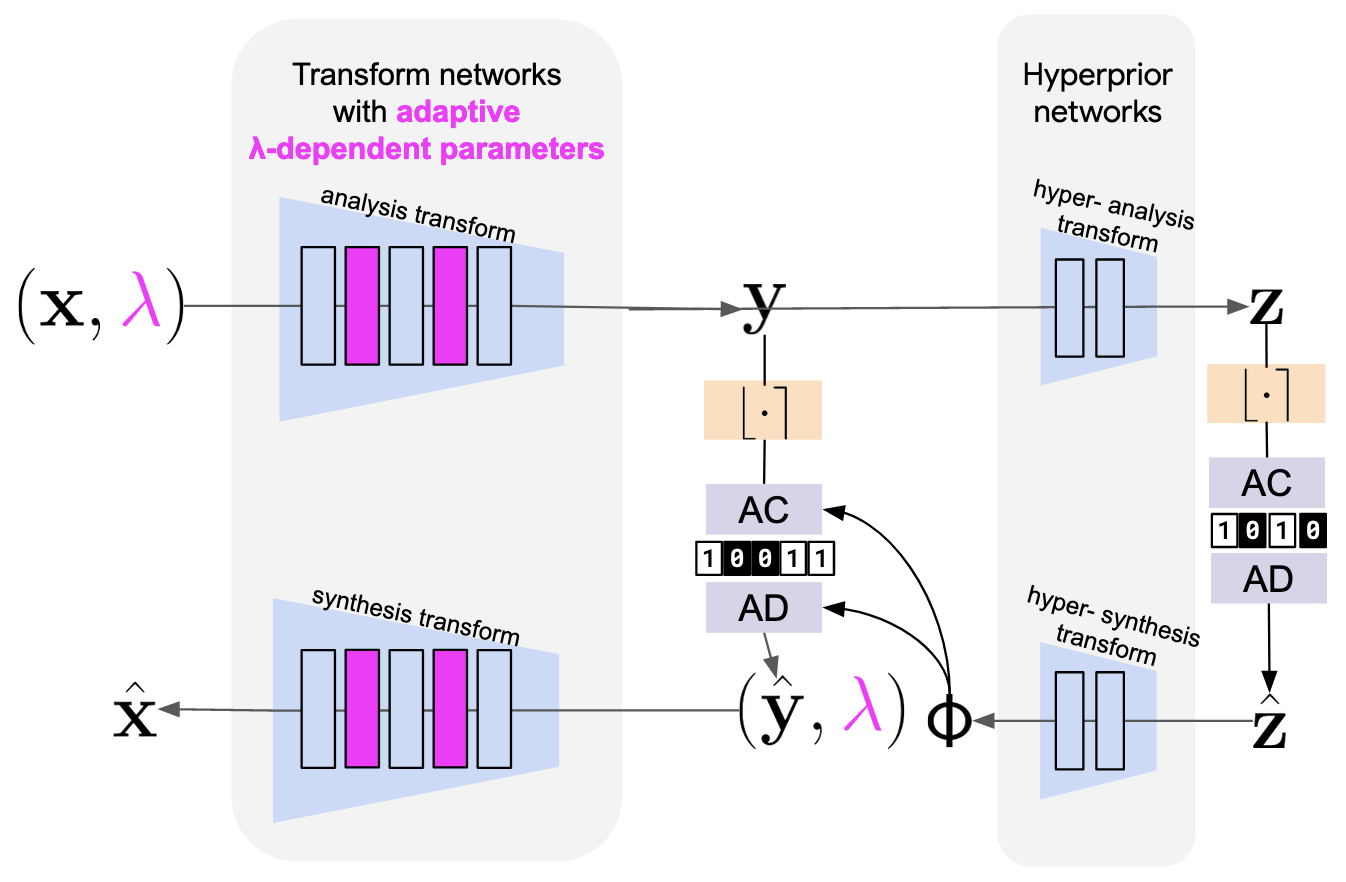
I wrote up the results for a conference paper, which was accepted to IEEE Int’l Conference on Acoustics, Speech and Signal Processing 2023 (ICASSP) taking place in Rhodes Greece (arXiv:2210.14308)! Figure 1 of the paper (below) shows the architecture of the model. I developed a method that serves as a (non)linear drop-in replacement for or augmentations to existing transform coding modules in the AV1 codec. The TL;DR is that a base autoencoder and hyperprior are trained on a large dataset of video frames prediction residuals. To allow the model to operate at different bit rates, we can train auxiliary parameters (gain modulations; pink) to control the rate-dependent output scale at each layer. In the paper, we show the model can be trained end-to-end, and that we can augment the DCT with learned gain modulations (quantization matrices), and hyperpriors to significantly improvement performance at a fraction of the cost of a full-blown nonlinear transform (e.g. a deep net).